
Hypothesis testing is a cornerstone of statistical analysis, allowing you to make data-driven decisions by evaluating the validity of a claim about a population parameter. Microsoft Excel, a powerful tool for data analysis, provides various built-in functions and tools to conduct hypothesis testing efficiently.
This blog delves into the essentials of hypothesis testing, types of tests, and step-by-step guides for performing them in Excel, with practical business-oriented examples. Here’s our example sheet for you to practice with: Statistical Hypothesis Tests in Excel.xlsx
What is Hypothesis Testing?
At its core, hypothesis testing evaluates whether an assumption (the null hypothesis) about a population parameter holds true, given sample data.
Key Terms in Hypothesis Testing:
- Null Hypothesis (H₀): Assumes no effect or no difference.
- Alternative Hypothesis (Hₐ): Indicates the presence of an effect or difference.
- Significance Level (α): The threshold for rejecting H₀, commonly set at 0.05 (5%).
- P-value: Probability of observing the sample results if H₀ is true.
- Test Statistic: A value calculated from the data to decide whether to reject H₀.
| Type of Hypothesis Test | Description | Excel Tool |
| One-sample t-test | Tests the mean of a single sample against a known value. | T.TEST Function |
| Two-sample t-test | Compares the means of two independent groups (with equal or unequal variance) . | T.TEST Function |
| Paired t-test | Compare the means of two related samples. | T.TEST Function |
| Z-test | Similar to t-tests but assumes a larger sample size or known population variance. | Z.TEST Function |
| Chi-square test | Tests relationships between categorical variables. | CHISQ.TEST Function |
| ANOVA | Compares means across multiple groups. | Analysis ToolPak Add-in |
| F-test | Compares the variances of two datasets to test for equal variance. | F.TEST Function |
Let’s explore these methods with business-centric examples.
1.T-Test In Excel
Syntax:
T.TEST(array1, array2, tails, type)
1. array1:
This is the first data range, representing the sample data you’re testing. In this case, it contains the observed diameters of bolts.
2. array2:
This is the second data range or comparison data. For a one-sample t-test, you should enter the hypothesized mean (e.g., 5) in all cells of this range. Excel compares the actual data (array1) with this comparison value.
3. tails:
This specifies whether the test is one-tailed or two-tailed:
- 1: One-tailed test
Used when you want to check if the sample mean is either greater than or less than the hypothesized mean (but not both).
Example: “Is the average diameter less than 5 mm?” - 2: Two-tailed test
Used when you’re checking for any difference (either higher or lower).
Example: “Is the average diameter different from 5 mm?”
Note: the values for 2 tail test is twice that of one-tail test.
4. type:
This specifies the type of t-test you are performing:
- 1: Paired t-test
Used when the two sets of data are related or paired (e.g., before and after scenarios). - 2: Two-sample t-test (equal variance)
Used to compare two independent groups assuming their variances are similar. - 3: Two-sample t-test (unequal variance)
Used to compare two independent groups when variances are different.
1. One-Sample T-test (Equal Variances)
Scenario: Quality Control in Manufacturing
A manufacturer claims the average diameter of machine-produced bolts is 5 mm. A sample of 10 bolts gives the following diameters (in mm). Now, Excel does not have a built-in one-sample t-test, but you can modify the two sample t-test and the data to achieve the same results. To do this, we must have a helper column in which the hypothesized mean (known value) is filled across all the rows as below:
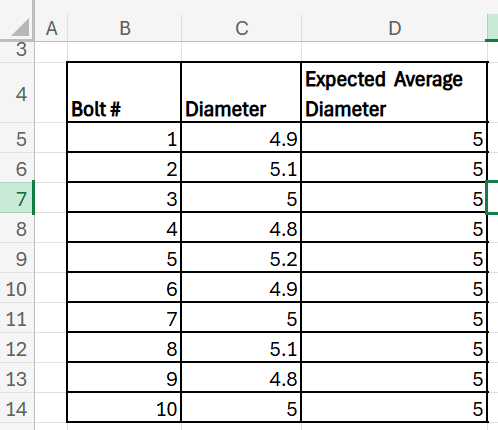
Steps:
- State the hypotheses:
- H₀: μ = 5 mm (average diameter is 5 mm).
- Hₐ: μ ≠ 5 mm.
2. Formula: =T.TEST(C5:C14,D5:D14,2,2)
Note: To test for equal variances, the rule of thumb is, if the ratio of the larger variance to the smaller variance is less than 4 then we can assume the variances are approximately equal. Otherwise, if the ratio is equal to or greater than 4, we assume that the variances are not equal.
Results:
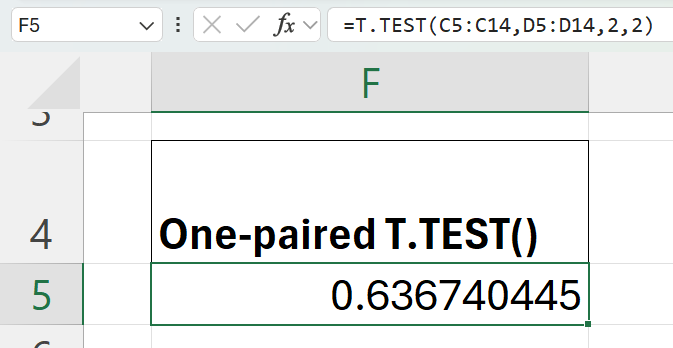
- If the p-value < α (e.g., 0.05), reject H₀.
- Since the p-value (0.6367) is greater than the typical significance level (e.g., 0.05), we fail to reject the null hypothesis (H₀).
- This means there is no significant difference between the sample mean and the hypothesized mean of 5 mm. The bolt diameters are almost consistent with the claimed standard.
2. Two-Sample t-Test (Unequal Variances)
Scenario: Employee Productivity
A company evaluates if productivity differs between two branches based on daily sales (in $):
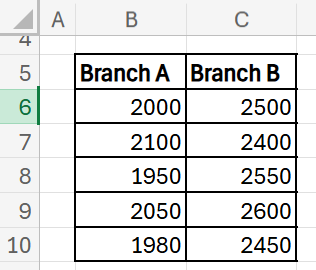
There are 50 such rows in this dataset.
Steps:
- State hypotheses:
- H₀: μ₁ = μ₂ (no difference in means).
- Hₐ: μ₁ ≠ μ₂ (means are different).
- Formula:
=T.TEST(B6:B55, C6:C55, 2,3)
Results:
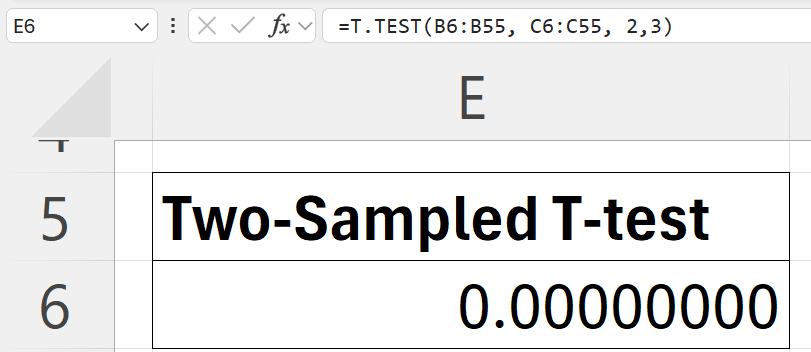
- p-value: = 0
- The p-value is far smaller than any typical significance level (α=0.05), so we reject the null hypothesis H0.
- This indicates a statistically significant difference in the average daily sales between Branch A and Branch B.
- Branch B’s daily sales are significantly higher than Branch A’s, confirming the productivity difference between the two branches.
3. Paired t-Test
Scenario: Pre- and Post-Training Assessment
The HR department evaluates the impact of training by comparing employee scores before and after training:
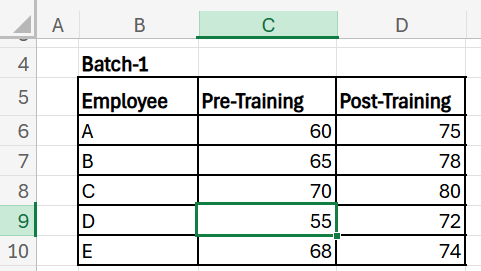
Steps:
- State hypotheses:
- H₀: μd = 0 (no difference).
- Hₐ: μd ≠ 0 (significant difference).
2.Formula:
=T.TEST(B2:B6, C2:C6, 2, 1)
- 1: Paired test type.
Results:
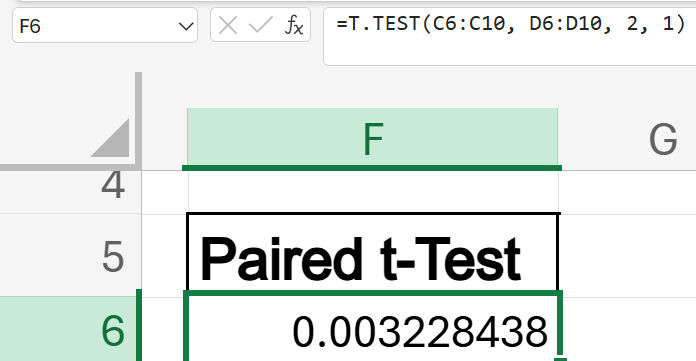
- The p-value is far smaller than the typical significance level (α=0.05), so we reject the null hypothesis H0.
- This indicates a statistically significant difference in the scores before and after training. The results suggest that the training program had a significant positive impact on the participants’ performance, as the post-training scores are notably higher than the pre-training scores.
However, say there was a second batch of employees that went through a different training program. We would like to know how effective this new training program has been. Let’s run a paired t-test on this new data as well:
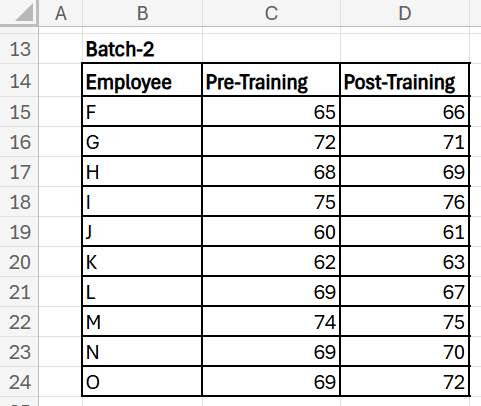
Result:
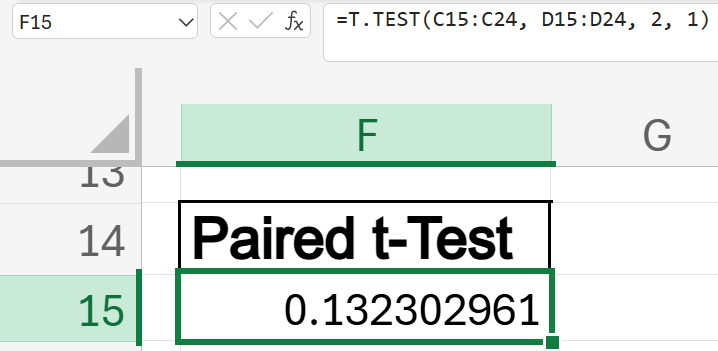
- Since the p-value (0.1323) is greater than α=0.05, we fail to reject the null hypothesis H0.
- The result suggests that there is no statistically significant difference between the pre-training and post-training scores for the new set of employees. This means that the new training program does not appear to have a significant impact on participants’ performance.
- In practical terms, the differences in scores could be due to random variation or other factors unrelated to the training.
**
2. Z-Test in Excel
The Z.TEST function in Excel is used to perform a one-sample z-test to determine whether a sample mean differs significantly from a hypothesized population mean, assuming the population standard deviation is known. For a specified hypothesized population mean (x), this function calculates the probability that the hypothesized mean is greater than the observed mean of the dataset (array).
Syntax:
Z.TEST(array, x, [sigma])
array (required):
- The range of sample data to be tested.
- Represents the sample for which you want to calculate the z-test.
x (required):
- The hypothesized population mean.
- The mean value you are testing the sample against.
sigma (optional):
- The population standard deviation.
- If omitted, Excel uses the sample standard deviation instead. Providing this value ensures that the z-test assumes the known population standard deviation.
Scenario: Customer Satisfaction
A company claims its average satisfaction score is 6 out of 10. It has been observed for the total population that the standard deviation was 2.5. Let’s take a look at how close the average satisfaction score of a sample of recent 50 customers (With mean of 6.3 and standard deviation 2.84) would be from this population mean.
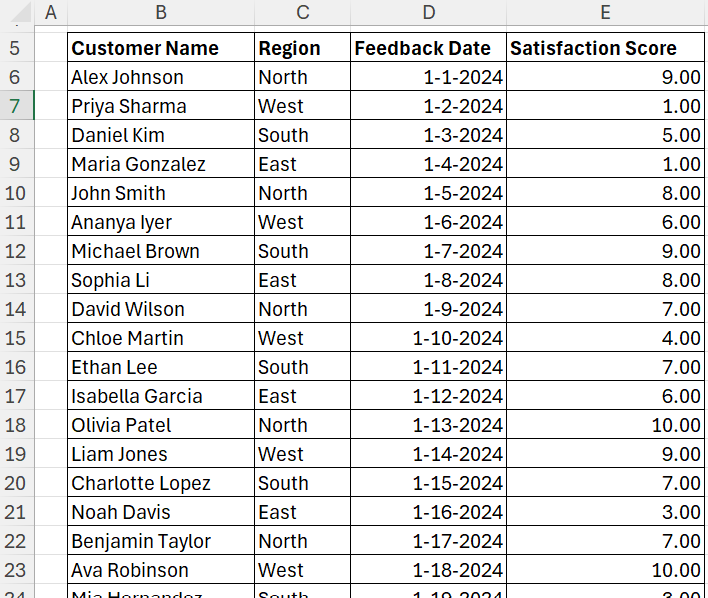
Steps:
- State hypotheses:
- H₀: hypothesis mean = sample mean (no significant difference).
- Hₐ: hypothesis mean > sample mean (significant difference).
- Formula:
=Z.TEST(E6:E55,6,2.5)
Results:
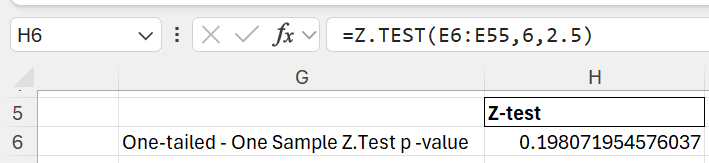
- The result is the p-value.
- If p-value < 0.05: Reject H₀ (the sample mean differs significantly from 6).
- If p-value ≥ 0.05: Fail to reject H₀ (no significant difference).
- Since the p-value derived (0.1781) is greater than α=0.05 (5-95% confidence interval), we fail to reject the null hypothesis. The result suggests that there is not much of a statistically significant difference between the hypothesised population mean (6) and the sample mean (6.3). As long as the hypothesised mean is close to the actual sample mean, the p-values would be close to 0.05 (with minor deviations of the left and right hand side of the distribution). This means the observed sample data supports the company’s claim that the average satisfaction score is 6. The slight difference between the sample mean (6.3) and hypothesised mean (6) is likely due to random variation rather than a true difference.
**
3. Chi-Square Test in Excel
Scenario: Learning Style Effectiveness
A school administrator wants to determine whether there is a relationship between students’ learning styles and gender (boys and girls). The study categorizes learning styles into Visual, Auditory, and Kinaesthetic. A survey of 146 students was conducted, and the observed distribution of boys and girls in each category was recorded. The administrator is interested in knowing if the learning style preferences are independent of gender or if there is a significant association between the two.
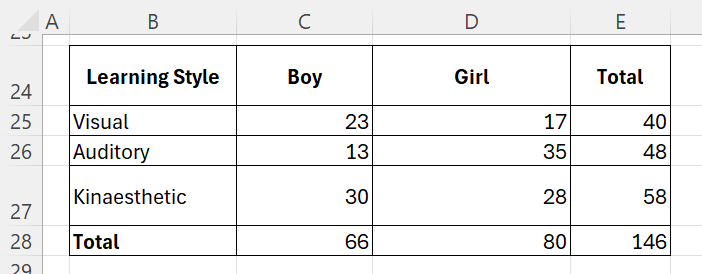
Step 1: Hypotheses
Regardless of what the categories are, you hypothesis must always be:
For our example,
- Null Hypothesis: There is no relationship between gender (boys and girls) and learning style preferences. Learning styles are independent of gender.
- Alternative Hypothesis: There is a significant relationship between gender and learning style preferences.
Step 2: Expected Frequencies
To calculate expected frequencies for each cell:
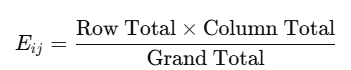
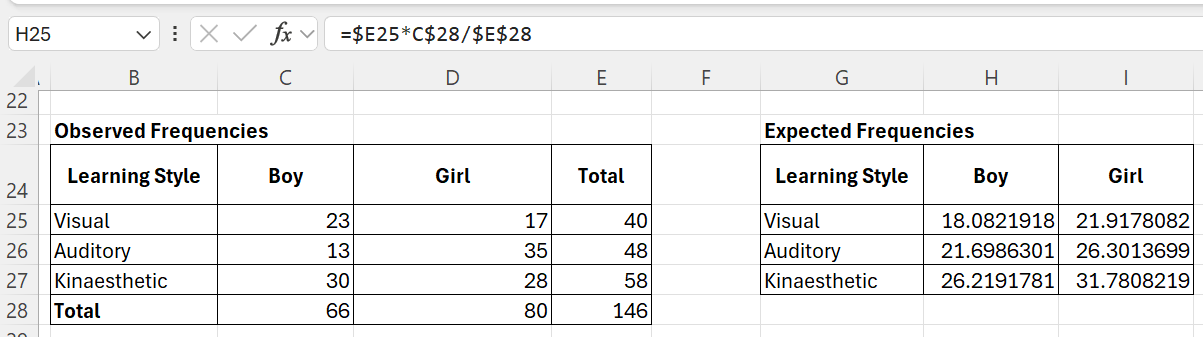
Step 3: Calculate Chi-Squared p-value
=CHISQ.TEST(C25:D27,H25:I27)
Where C25:D27 is the observed values range and H25:I27 is the expected value range.
Results:
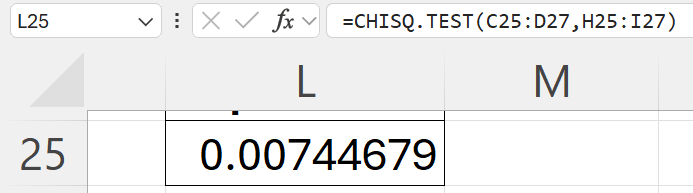
Let’s assume a common significance level (α) of 0.05:
- If the p-value is less than 0.05, reject the null hypothesis.
- If the p-value is greater than or equal to 0.05, fail to reject the null hypothesis.
Interpretation
- p<0.05: Reject the null hypothesis.
- Conclusion: There is a significant relationship between gender and learning style. Perhaps in overall terms, boys learn better visually and kinaesthetically than girls whereas girls learn better through audio.
**
4. F.Test in Excel
The F.TEST function calculates the P-value for an F-test, which is used to test whether the variances of two datasets are significantly different from each other. You use F.TEST when you simply want to know whether the variances between two groups are different, without calculating the actual F-statistic manually. The function helps you quickly determine if you should reject or fail to reject the null hypothesis based on the P-value.
In the context of data analysis, comparing the variance of two datasets can help answer important questions, such as whether one group has more variability than the other. For instance, comparing the performance of two departments, evaluating the stability of sales data across different regions, or determining the consistency of customer satisfaction scores between two product lines. Note that the F.TEST function does not return the F test value, instead it returns its probability.
Syntax:
F.TEST(array1, array2)
Scenario: Sales Teams Performances
You are comparing the sales performance of Team A and Team B over 5 weeks. You want to perform an F-test to see if there is a significant difference in the variance of sales between the two teams.
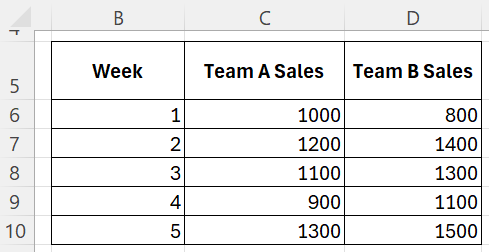
Formula:
=F.TEST(C6:C10,D6:D10)
Results:

- The result is the p-value.
- If the P-value is < 0.05: Reject the null hypothesis (the variances are significantly different).
- If the P-value is > 0.05: Fail to reject the null hypothesis (no significant difference in variances).
- Since the p-value derived (0.518) is much greater than α=0.05, we fail to reject the null hypothesis. This means that the data does not provide sufficient evidence to say the variances are equal.
- If one team’s sales have a higher variance, it might indicate inconsistency due to fluctuating external factors or internal dynamics.
Now, if I find the one-tailed F-Statistic using the Analysis Toolpak in Excel (will be covered in the upcoming section), here’s what we see:
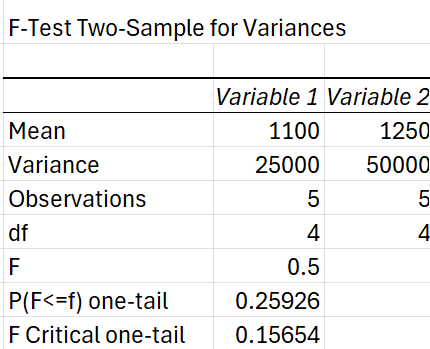
The F-statistic (by dividing the larger variance by the smaller variance), we get a value of 0.5. The critical value, which we calculated using this Toolpak l in Excel, is 0.15654. Since the F-statistic is more than the F-critical value, we fail to reject the null hypothesis.
This is essentially the same process we follow when using the F.TEST function in Excel. If the result of the F.TEST function is greater than 0.05, we do not reject the null hypothesis. If the result is less than 0.05, we reject the null hypothesis.
P(F ≤ f) one-tail is the probability that an observed F-statistic (F = 0.5 in this case) is less than or equal to the given significance value (0.5) under the null hypothesis. It is calculated based on the F-distribution with the specified degrees of freedom (df1 = 4, df2 = 4). The value 0.2592590 tells us the likelihood of observing an F-statistic as small or smaller than 0.5 if the null hypothesis is true.
To calculate the Two-tailed p-value for this distribution, you can use use the below formula:
Two-tailed p-value=2×min(P(F ≤ f),P(F > f))
Where P(F > f)=1−P(F ≤ f)
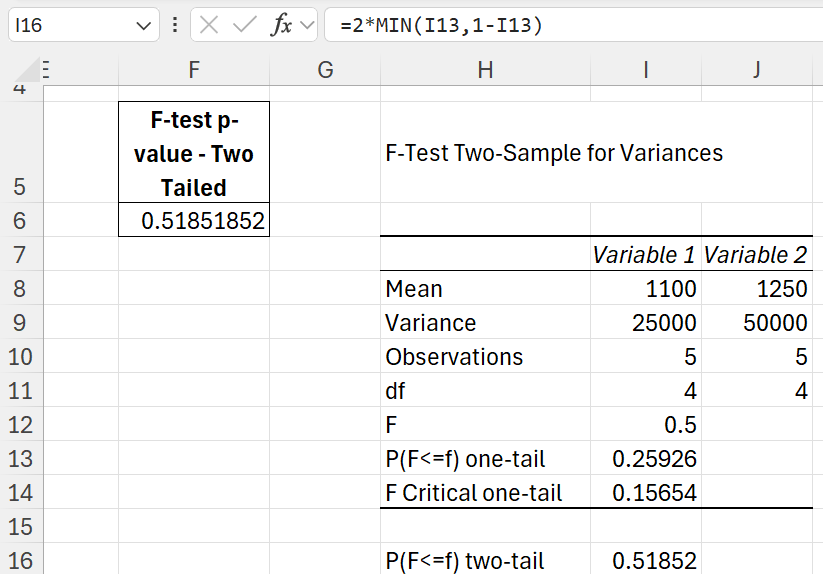
In the above example, we notice that P-value for one tail test is 0.25926 and P-value for two tail test is twice of that 0.51852 (=2*0.25926)
So, this is how we use the F.TEST function in Excel. It was introduced in Excel 2010, whereas earlier versions had the FTEST function. While FTEST is still available in Excel, Microsoft recommends using the F.TEST function instead.
**
5. ANOVA in Excel
ANOVA (Analysis of Variance) is a statistical method used to determine if there are significant differences between the means of three or more independent groups. While methods like the t-test compare means between two groups, ANOVA extends this capability to multiple groups, making it a crucial tool for comparing data in scenarios where more than two categories are involved.
In Excel’s Analysis ToolPak, there are three types of ANOVA (Analysis of Variance) tests available. These tests are used to analyze the differences between group means and determine if the means are statistically different from each other. Here’s an overview of the three types of ANOVA available in Excel and where each should be used:
| ANOVA Type | When to Use | Example |
| One-Factor ANOVA | To compare the means of 3 or more independent groups based on one factor. | Comparing weight loss across 3 different diets (Low Carb, High Carb, Vegan) with multiple participants per diet. |
| Two-Factor ANOVA Without Replication | To compare the effects of 2 factors with one observation per factor combination. | Studying the impact of Diet Type and Exercise Regimen on weight loss with a single observation per diet/exercise combination. |
| Two-Factor ANOVA With Replication | To compare the effects of 2 factors with multiple observations for each combination of factors. | Studying the impact of Diet Type and Exercise Regimen on weight loss with multiple participants for each combination. |
Key Applications
- Comparing group performance (e.g., student scores across different classes).
- Testing product effectiveness (e.g., customer satisfaction for different product lines).
- Assessing regional differences (e.g., sales performance across geographic regions).
How ANOVA Works
- Hypotheses:
- Null Hypothesis : All group means are equal.
- Alternative Hypothesis: At least one group mean differs.
- Logic:
- ANOVA examines the variance within each group (how data points deviate from their group mean) and the variance between groups (how group means differ from the overall mean).
- If the variance between groups is significantly larger than the variance within groups, it suggests a difference in group means.
Why Use ANOVA?
ANOVA simplifies comparisons across multiple groups in a single test, reducing the risk of errors from running multiple pairwise t-tests. For instance, if you’re comparing sales performance across North, South, East, and West regions, ANOVA is more efficient and statistically robust.
a) ANOVA with Single Factor:
Scenario: Comparing Sales Across Regions
A company evaluates if average sales differ across three regions:
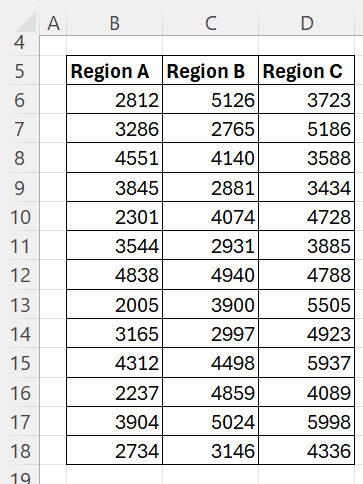
Steps:
- Install Analysis ToolPak:
- Go to File > Options > Add-ins.
- Select Analysis ToolPak and click OK.
- Navigate to Data > Data Analysis > ANOVA: Single Factor.
- Input the range and group the data by columns.
Key Terms in ANOVA Output
1. Summary Table:
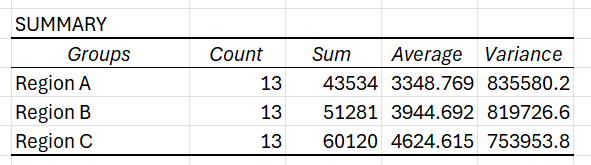
- Groups: Lists the groups being compared (e.g., Region A, Region B, Region C).
- Count: Number of observations in each group.
- Sum: Total sum of the sales values for each group.
- Average: Mean (average sales) for each group.
- Variance: Measure of variability within each group.
ANOVA Table:
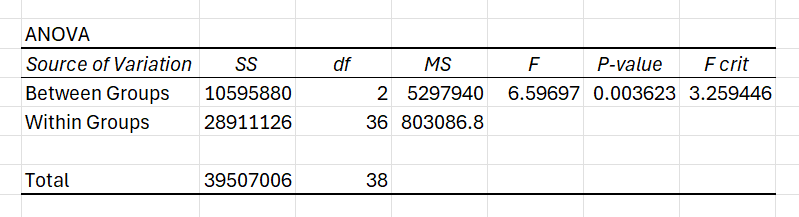
- Sources of Variation:
- Between Groups: Variance due to differences in group means.
- Within Groups: Variance within each group (individual data points compared to their group mean).
- SS (Sum of Squares): Total variability for each source (larger values mean more variability).
- df (Degrees of Freedom): Number of independent values for each source.
- MS (Mean Square): Average variability (calculated as SS/df).
- F (F-Ratio): Ratio of between-group variability to within-group variability.
- P-value: Probability of observing the results if H0 (all group means are equal) is true.
- F crit (Critical Value): Threshold value; if F > FCrit, reject H0.
Interpreting the Results
- P-value:
- If P-value < 0.05 (significance level): Reject the null hypothesis (H0), indicating that there is a significant difference between the group means.
- If P-value ≥ 0.05: Fail to reject H0, suggesting no significant difference between the group means.
- Example Interpretation:
- P-value = 0.007: Since 0.007<0.05, reject H0. This means the average sales differ significantly across regions.
- F-Statistic and F Critical:
- Compare the F-statistic with F crit:
- If F > F crit: Reject H0, meaning significant differences exist.
- If F ≤ F crit: Fail to reject H0.
- Compare the F-statistic with F crit:
- Example Interpretation:
- F = 5.20, F crit = 3.15: Since 5.20>3.15, we reject H0, confirming significant differences in sales means.
Based on these observations, we can say that the average sales differ significantly across the three regions.
b) ANOVA: Two Factors Without Replication
Since this is a two-factor ANOVA without replication, there is only one observation for each combination of the factors (i.e., each diet type and exercise regimen combination). This type of design can still provide insight into the main effects of each factor and their interaction but has limitations, as it doesn’t allow for statistical testing of the interaction with replication.
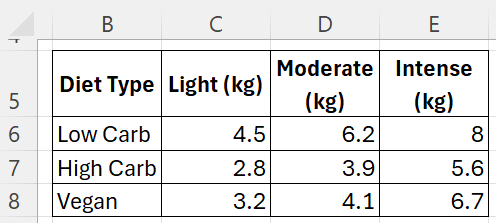
In this format:
- Rows represent the Diet Type (Low Carb, High Carb, and Vegan).
- Columns represent the Exercise Regimen (Light, Moderate, and Intense).
- The values in the table are the Weight Loss (in kilograms) for each combination of Diet Type and Exercise Regimen.
Steps:
- Navigate to Data > Data Analysis > ANOVA: Two Factors Without Replication.
- Input the requested range and group the data by columns.
Key Terms in ANOVA Output
Summary Table:
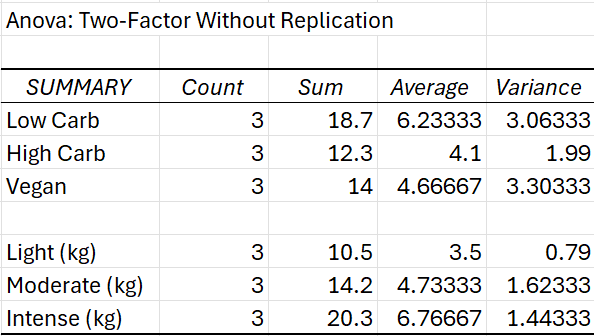
This summary is showing the central tendencies (mean) and the variability (variance) of the data for each combination of diet type and activity level. The ANOVA is likely testing whether there are statistically significant differences between:
- The different diet types (Low Carb, High Carb, Vegan).
- The different exercise intensity levels (Light, Moderate, Intense).
Each of the means (average values) suggests a comparison of how diet and activity level may influence the outcome variable (possibly weight loss or another metric measured in kg). The variances show how much the individual data points deviate from the mean within each group, with higher variance indicating more spread in the data.
ANOVA Table:
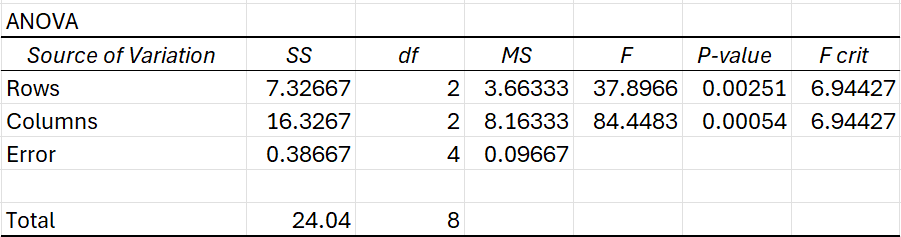
Key Components of the Output:
- Source of Variation:
- Rows: This refers to the effect of the first factor (e.g., different diet types: Low Carb, High Carb, Vegan).
- Columns: This refers to the effect of the second factor (e.g., different activity levels: Light, Moderate, Intense).
- Error: This represents the residual or unexplained variation that is not attributed to the factors (rows or columns).
- Total: This is the total variation in the data, which is the sum of the variation from rows, columns, and error.
- SS (Sum of Squares):
- This measures the variation explained by each source (rows, columns, and error).
- Rows (7.33): Variation due to differences between the diet types.
- Columns (16.33): Variation due to differences between the activity levels.
- Error (0.39): Variation due to random error or factors not included in the model.
- Total (24.04): The total variation in the data.
- df (Degrees of Freedom):
- The degrees of freedom associated with each source of variation.
- Rows (2): There are 3 diet types, so 2 degrees of freedom (3-1 = 2).
- Columns (2): There are 3 activity levels, so 2 degrees of freedom (3-1 = 2).
- Error (4): The total number of data points minus the number of treatments (degrees of freedom for error = (3 rows × 3 columns) – (3 rows + 3 columns) = 9 – 5 = 4).
- Total (8): The total number of data points minus 1 (9 – 1 = 8).
- MS (Mean Square):
- The mean square is the sum of squares (SS) divided by the degrees of freedom (df).
- F-Statistic (F):
- The F-statistic is the ratio of the mean square of the factor to the mean square of the error. It is used to test if there are significant differences between the means of the groups.
- A larger F-value indicates a greater likelihood that the factor is having a significant effect on the dependent variable.
- P-Value:
- The P-value indicates the probability of obtaining an F-statistic as extreme as, or more extreme than, the observed value under the null hypothesis (which assumes no effect).
- Rows (0.0025): This is less than the typical significance level of 0.05, so we reject the null hypothesis for the rows (diet type). This indicates that the diet types significantly affect the dependent variable.
- Columns (0.0005): Similarly, this is also less than 0.05, so we reject the null hypothesis for the columns (activity level). This suggests that activity level also has a significant effect on the dependent variable.
- F Crit (Critical F-Value):
- This is the critical value of the F-distribution at a certain significance level (usually 0.05). If the calculated F-statistic exceeds this value, we reject the null hypothesis.
- For both rows and columns, the F critical value is 6.94. Since both F-statistics (37.90 and 84.45) are much larger than the critical value, the results are significant.
Summary:
- Diet Type (Rows) and Exercise Regimen (Columns) both significantly affect Weight Loss since both have very low p-values (< 0.05 (chosen significance values)) and large F-values.
- The F-values are much greater than the critical F-values, meaning there is heavy dependence between the two predictor variables and weight loss. This supports that both factors have significant impacts on the outcome variable.
- Interaction Effects are not provided in this case (since it’s a two-factor ANOVA without replication), but you can still conclude that each factor (Diet Type and Exercise Regimen) has a substantial main effect on the outcome.
In conclusion, both diet type and activity level significantly influence the outcome being measured, and further analysis could explore the nature of these effects.
c) ANOVA: Two Factors With Replication
Now let’s study the effect of Diet Type (Low Carb, High Carb, Vegan) and Exercise Regimen (Light, Moderate, Intense) on Weight Loss, with multiple subjects for each combination of Diet Type and Exercise Regimen.
Use Two-Factor ANOVA With Replication when you have two factors and multiple observations for each factor combination. This test is similar to the Two-Factor ANOVA Without Replication, but it includes replication, meaning there are multiple observations for each combination of the two factors. Replication allows for more accurate estimation of variability and testing of interactions. One assumption of this test is that the design is balanced (i.e., the number of replicates for each combination of factors is equal).
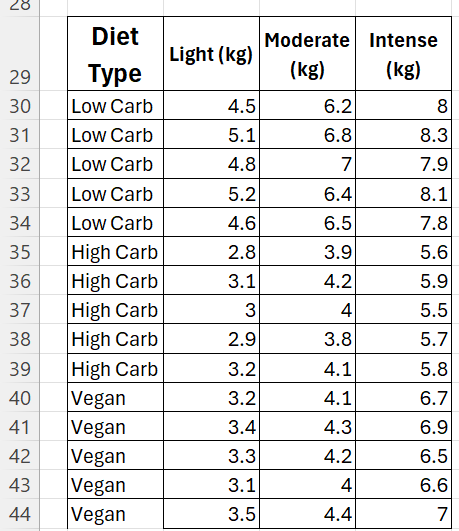
Steps:
- Navigate to Data > Data Analysis > ANOVA: Two Factors With Replication.
- Input the requested range, sample would be the number of repetitions for each category of your first factor (5 in our case for every diet type).
Key Terms in ANOVA Output
Summary Table:
This shows the summary statistics (count, sum, average, and variance) for each combination of factors (diet type and activity level):
- Low Carb, High Carb, and Vegan each have 5 observations (count) for each activity level (Light, Moderate, Intense).
- Average values indicate the mean outcome for each combination of diet type and activity level.
- Variance measures the spread of data within each group (lower variance indicates more consistency in the data).
ANOVA Table:
The ANOVA table provides statistical tests to evaluate whether the two factors (diet and activity level) significantly affect the dependent variable, and whether there is an interaction between them.
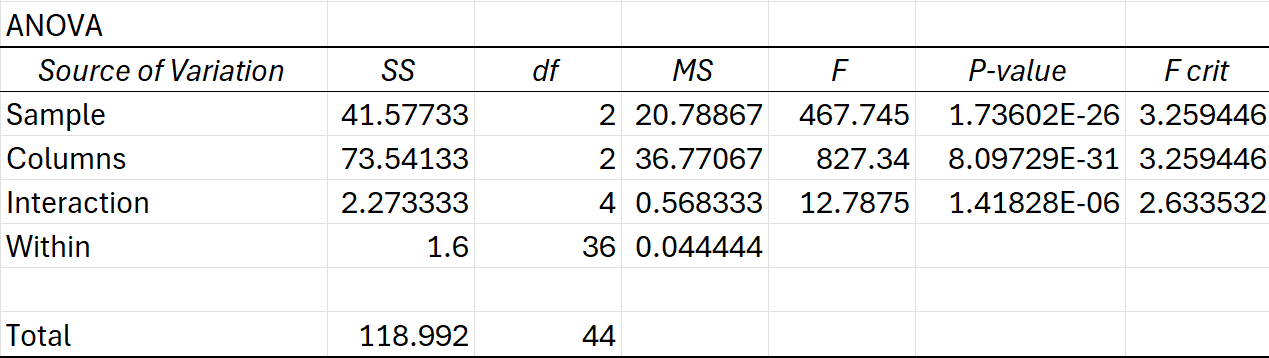
- Source of Variation:
- Sample: Refers to the main effect of the diet types (Low Carb, High Carb, Vegan).
- Columns: Refers to the main effect of the activity levels (Light, Moderate, Intense).
- Interaction: This tests whether there is an interaction effect between diet type and activity level.
- Within: Refers to the variation within each group (i.e., random error).
- Sum of Squares (SS):
- Measures the total variation attributed to each factor or the interaction.
- Sample (41.58): Variation due to differences between diet types.
- Columns (73.54): Variation due to differences between activity levels.
- Interaction (2.27): Variation due to the interaction between diet type and activity level.
- Within (1.60): Variation due to random error within groups.
- Degrees of Freedom (df):
- The degrees of freedom for each source of variation.
- Sample (2): There are 3 diet types, so 2 degrees of freedom (3 – 1 = 2).
- Columns (2): There are 3 activity levels, so 2 degrees of freedom (3 – 1 = 2).
- Interaction (4): This is the number of combinations of diet types and activity levels minus the number of factors (2 * 3 – 2 – 2 = 4).
- Within (36): The total number of observations minus the number of groups (15 × 3 – 9 = 36).
- Mean Square (MS):
- The mean square is the sum of squares divided by the degrees of freedom.
- Sample (20.79): 41.582\frac{41.58}{2}241.58
- Columns (36.77): 73.542\frac{73.54}{2}273.54
- Interaction (0.57): 2.274\frac{2.27}{4}42.27
- Within (0.04): 1.6036\frac{1.60}{36}361.60
- F-Statistic (F):
- The F-statistic is the ratio of the mean square for each factor (or interaction) to the mean square for the error term (Within).
- The F-statistics are very large, indicating strong effects from the factors and their interaction.
- P-value:
- The P-value tests whether the observed F-statistics are statistically significant.
- Sample (1.736 × 10⁻²⁶): This is extremely small and much less than the typical significance level of 0.05, indicating that the diet type (rows) has a highly significant effect on the dependent variable.
- Columns (8.097 × 10⁻³¹): This is also extremely small, indicating that activity level (columns) has a highly significant effect as well.
- Interaction (1.418 × 10⁻⁶): This is also very small, indicating that the interaction between diet type and activity level is highly significant. This means the effect of diet on the dependent variable may depend on the activity level.
- F critical (F crit):
- The F critical value is the threshold value for the F-statistic. If the calculated F-statistic exceeds this critical value, the result is significant.
- Sample (3.26), Columns (3.26), and Interaction (2.63): Since the calculated F-statistics (467.75, 827.34, and 12.79) are all much larger than the critical values, we can reject the null hypothesis for each source (diet type, activity level, and interaction). This confirms that all three factors have statistically significant effects.
Interpretation:
- Main Effects:
- Diet Type (Sample): The differences between the diet types (Low Carb, High Carb, Vegan) significantly affect the dependent variable.
- Activity Level (Columns): The differences between activity levels (Light, Moderate, Intense) also significantly affect the dependent variable.
- Interaction: There is a statistically significant interaction between diet type and activity level. This means that the effect of diet type on the dependent variable (kg) depends on the level of activity, and vice versa.
- Both diet type and activity level significantly influence the dependent variable (kg).
- Additionally, there is a significant interaction between the two factors, meaning that the combined effects of diet and activity level on the outcome are not simply additive but depend on each other.
- The results suggest that you may need to consider both factors together when designing a diet and exercise plan, as the effects are not independent.
**
Visualisation of Results of Statistical Testing
Use charts to represent hypothesis testing outcomes:
- Box plots: Compare distributions for t-tests or ANOVA.
- Bar charts: Represent categorical data for chi-square tests.
Key Factors in Choosing a Statical Hypothesis Test in Excel
- Type of Data:
- Numerical (e.g., height, income): t-tests, ANOVA.
- Categorical (e.g., gender, preferences): Chi-Square.
- Number of Groups:
- Two groups: t-tests.
- More than two groups: ANOVA.
- Assumptions:
- Normality: t-tests, z-tests, ANOVA.
- No normality: Advanced tests like Mann-Whitney, Kruskal-Wallis.
- Sample Size:
- Small samples: t-tests.
- Large samples: z-tests, Chi-Square.
Best Practices for Hypothesis Testing in Excel
- Clean Data: Remove duplicates and handle missing values.
- Use Named Ranges: Make formulas easier to read.
- Check Assumptions: Ensure normality and equal variance for parametric tests.
- Automate Tests: Use dynamic ranges for scalable analyses.
FAQs
1. Can Excel handle non-parametric tests?
Excel doesn’t natively support non-parametric tests like Mann-Whitney U or Wilcoxon Signed-Rank. However, you can calculate these manually or use add-ins.
2. What are the limitations of hypothesis testing in Excel?
- Lack of built-in functions for advanced tests (e.g., logistic regression).
- Limited visualization options compared to tools like R or Python.
3. How to interpret p-values?
- If p-value < α, reject H₀.
- If p-value ≥ α, fail to reject H₀.
Conclusion
Hypothesis testing is a powerful method for validating data-driven claims. Excel’s statistical functions and add-ins make it a practical choice for conducting these tests in business contexts. By following the steps outlined in this blog, you can confidently perform hypothesis testing and make informed decisions.
Download our free practice sheet to start today: Statistical Hypothesis Tests in Excel.xlsx!

