
Excel, a powerful tool for data analysis, offers a wide range of statistical functions to help you make informed decisions. These functions can be used to calculate descriptive statistics, probability distributions, and more. In this comprehensive guide, we will explore the most commonly used statistical functions, their applications, and their limitations. Here’s our follow-along practice sheet: Statistical Functions in Excel.xlsx
Understanding Statistical Functions in Excel
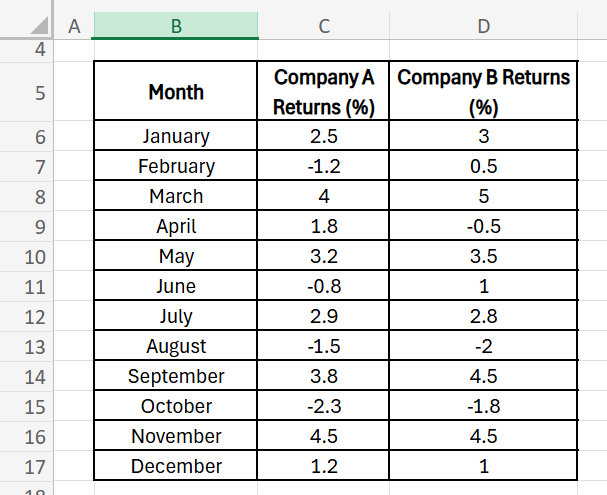
Statistical functions in Excel are designed to perform various calculations on numerical data. They can be categorised into several groups. Let’s take a look at how all these functions work on a financial dataset such as below:
Descriptive Statistics: Most commonly used functions in Excel
For a real-life example that a statistician might encounter, let’s use a financial dataset focusing on stock returns. We’ll analyse the historical monthly returns (in %) of two companies – Company A and Company B, over a one-year period. We’ll try to understand trends, volatility, correlations, and other statistical measures relevant for portfolio analysis.
1. AVERAGE(number1, [number2], …): Calculates the arithmetic mean of a range of cells.
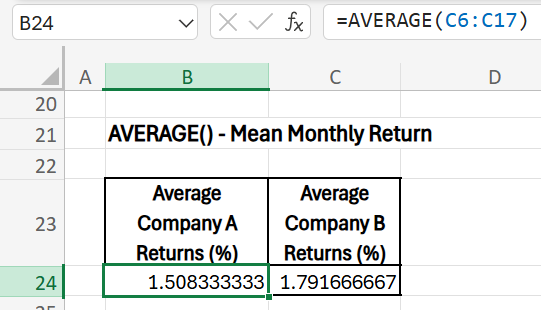
Mean Monthly Return
- Purpose: The average return gives a baseline for expected monthly performance. In finance, this is critical for predicting returns and planning future investments. If Company A’s average monthly return is higher than other investments with a similar risk profile, it may attract investors. Average returns are also a key indicator for budgeting and forecasting.
- Formula (Company A): =AVERAGE(C6:C17)
- Formula (Company B): =AVERAGE(D6:D17)
- Result:
2. MEDIAN(number1, [number2], …): Finds the middle value in a set of numbers.
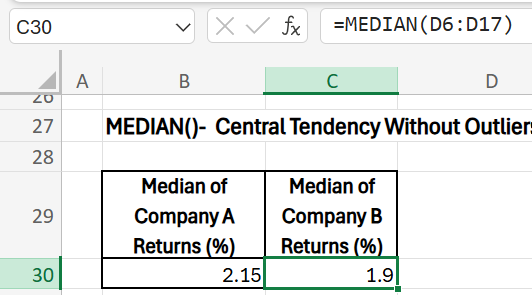
Understanding the Central Tendency Without Outliers
- Purpose: To find the median monthly return, which is less affected by outliers. Unlike the mean, the median is not affected by extreme values, giving a better measure of central tendency when outliers are present. If Company A’s median return is close to its average return, it suggests consistent performance. However, if there’s a large gap, investors may want to investigate the cause of volatility before deciding to invest.
- Formula (Company A): =MEDIAN(C6:C17)
- Formula (Company B): =MEDIAN(D6:D17)
- Results:
3) MODE(number1, [number2], …): Determines the most frequently occurring value. The first encountered most-repeated value in a sequence is chosen as the mode. In other words, a top-down approach is followed when deciding on a mode.
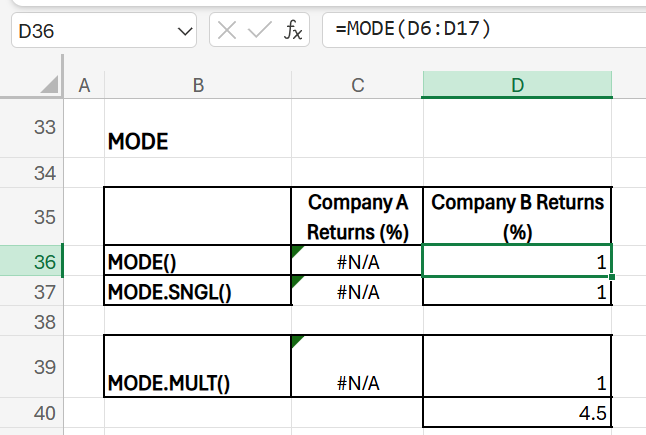
Most Common Monthly Return
- Purpose: Find the most frequently occurring monthly return. This is less common with financial data but can still reveal a recurring return value. Finding the mode helps to identify the most frequently occurring outcome, giving insight into “typical” returns. If a specific return (e.g., 2.5%) is common, business leaders may rely on it as a base-case scenario for forecasting and risk management. Knowing typical returns allows businesses to set realistic expectations and allocate resources accordingly.
- Formula (Company A): =MODE(C6:C17)
- Formula (Company B): =MODE(D6:D17)
Here, you see #N/A value for company A as all the stock values are distinct for that company.
Excel introduced MODE.SNGL and MODE.MULT in the latest version in response to the need for more flexible statistical analysis, especially with multimodal datasets where multiple values might appear with the highest frequency. Previously, the original MODE function could only return a single mode, which was limiting for data sets with more than one peak. By adding MODE.SNGL, Excel retained the functionality of the original MODE function to return a single mode, making it backward-compatible for users accustomed to the older function. MODE.MULT, however, brought a new capability by allowing users to see multiple modes in a single formula output.
In case there might be multiple values repeated the same number of times, MODE.MULT will give you the apt result.
MODE.SNGL returns the most frequently occurring value in a range, outputting a single result. The first encountered most-repeated value in a sequence is chosen as the mode. In other words, a top-down approach is followed when deciding on a mode.
MODE.MULT returns an array of the most frequently occurring values, useful when multiple modes exist. As seen in MODE.SNGL, the first-encountered most-repeated value in a sequence is chosen as the first mode and the next most-repeated value in a sequence is chosen as the second mode and so on.
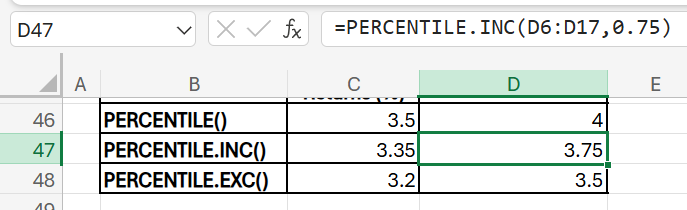
4) PERCENTILE(data, percentile): Returns the percentile for a data set based on the inclusive methods. Percentile calculations are used to understand the relative standing of a value within a data set. Specifically, percentiles divide your data into 100 equal parts, and each percentile indicates the value below which a certain percentage of the data falls. For example, In a dataset of 100 test scores, the 25th percentile is the score below which 25% of the students scored. If someone scored at the 75th percentile, they scored better than 75% of all students.
75th Percentile of Monthly Returns
- Purpose: Identify a high threshold return that 75% of the months fall below.
- Formula (Company A): =PERCENTILE(C6:C17, 0.75)
- Formula (Company B): =PERCENTILE(D6:D17, 0.75)
In the context of Company A’s returns, it means that 75% of the returns in the dataset are less than or equal to 3.35, and 25% of the returns are greater than 3.35.
Excel introduced PERCENTILE.INC and PERCENTILE.EXC to provide more flexibility and precision in calculating percentiles in data sets, especially for cases where the desired percentile might fall at or beyond the exact data limits. Previously, the PERCENTILE function offered a basic percentile calculation, but it lacked options for different boundary behaviours.
With PERCENTILE.INC (short for “inclusive”), Excel calculates percentiles by including both the minimum and maximum of the dataset’s range. This makes it ideal for general statistical purposes, where you want to include all data points. It gives the same result as PERCENTILE(). PERCENTILE.EXC (short for “exclusive”), on the other hand, calculates percentiles by excluding the dataset’s minimum and maximum values, offering a stricter statistical approach that is more appropriate when analysing population-based data with potentially skewed extremes.
PERCENTILE.INC includes the 0th and 100th percentiles in the calculation, while PERCENTILE.EXC excludes the 0th and 100th percentiles, only considering values between them.
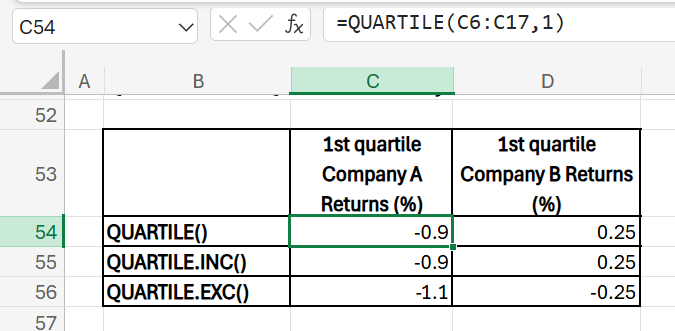
5) QUARTILE.INC(array, quart): returns the quartile for a data set using the inclusive method. Quartile.INC divides the data into four equal parts, with quartiles at the 25th, 50th, and 75th percentiles. The 1st quartile (Q1), representing the value that corresponds to the lower 25%.
First Quartile of Monthly Returns
- Purpose: Calculate the third quartile, which is the same as the 25th percentile in this case.
- Formula (Company A): =QUARTILE(C6:C17, 1)
- Formula (Company B): =QUARTILE(D6:D17, 1)
For company A, =QUARTILE(C6:C17, 1) returns a value of -0.9% which means that 25% of the stocks return in the range below -0.9. In other words, 75% of the returns are higher than -0.9.
In the newly introduced, QUARTILE.INC includes the 0th and 100th percentiles (i.e., the minimum and maximum values) in the calculation of quartiles, while QUARTILE.EXC excludes the 0th and 100th percentiles, only considering the values in between. QUARTILE.INC gives the same result as QUARTILE.
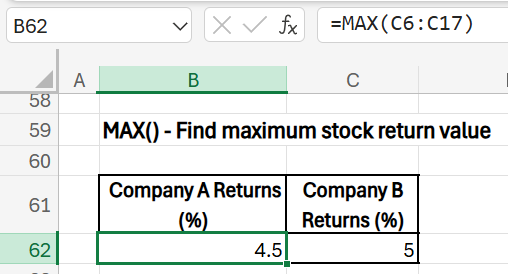
6) MAX([array1],[array2]…): Find the highest value in a range.
- Purpose: Identify the highest monthly return within the year for each company. This helps in understanding peak performance periods and the maximum potential gain.
- Formula (Company A): =MAX(C6:C17)
- Formula (Company B): =MAX(D6:D17)
- Results:
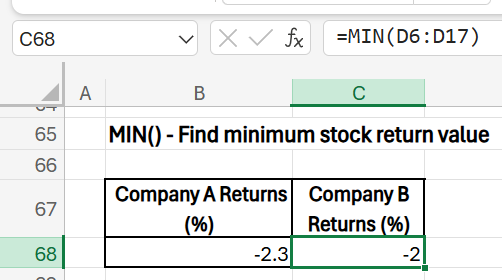
7) MIN([array1],[array2]…): Find the least value in a range.
- Purpose: Identify the lowest monthly return within the year for each company. This helps in understanding lowest performance periods and the minimum potential gain.
- Formula (Company A): =MIN(C6:C17)
- Formula (Company B): =MIN(D6:D17)
- Results:
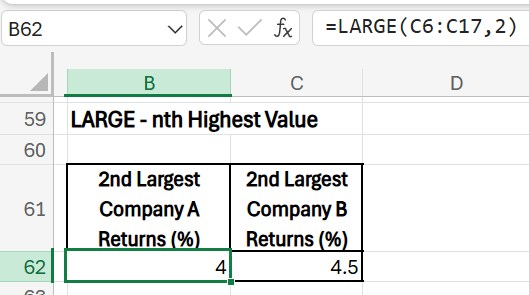
8) LARGE(array, k): Find the nth-highest value, useful for understanding extreme values. Please note that the second argument is compulsory in this function.
2nd Largest Monthly Return
- Purpose: Find the second-highest monthly return for each company.
- Formula (Company A): =LARGE(C6:C17, 2)
- Formula (Company B): =LARGE(D6:D17, 2)
- Results:
9) SMALL(array, k): Find the nth-lowest value, useful for understanding extreme values. Please note that the second argument is compulsory in this function.
2nd Smallest Monthly Return
- Purpose: Find the second-lowest monthly return, useful for understanding extreme values.
- Formula (Company A): =SMALL(C6:C17, 2)
- Formula (Company B): =SMALL(D6:D17, 2)
- Result:

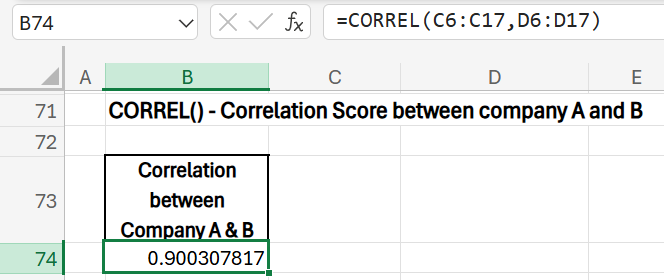
10) CORREL(array1, array2): Assess the direction of the relationship between two ranges.
Correlation Between Monthly Returns
- Purpose: Assess the direction of the relationship between the returns of the two companies (negative or positive).
- Formula: =CORREL(C6:C17, D6:D17)
- Result: 0.90 (A positive correlation indicates both stocks tend to move in the same direction.)
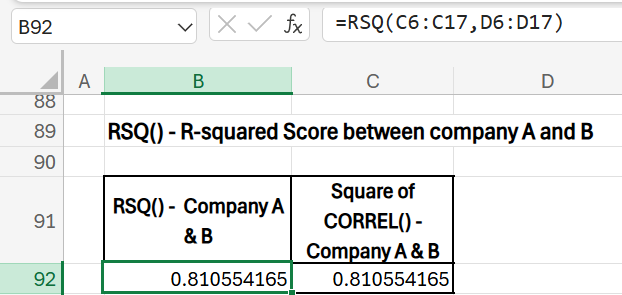
12) RSQ(array1, array2): Assess the strength of the relationship between the returns of the two companies.
Determine the Strength of the Relationship Between Two Variables
- Purpose: Use the RSQ function to assess how strongly the returns of the two companies are related by calculating the R-squared value. This value represents the proportion of variance in one company’s returns that can be explained by the variance in the other’s returns. This is the squared value of the correlation between two variables.
- Formula: =RSQ(C6:C17, D6:D17)
- Result: 0.81
A result of 0.81 indicates that 81% of the variance in Company A’s returns can be explained by Company B’s returns. This high R-squared value suggests a strong predictive relationship between the two stocks’ returns, meaning that when Company B’s returns change, Company A’s returns tend to change in a similar way. This insight can be useful in risk management and portfolio construction, as high R-squared values imply that the stocks are highly aligned, reducing the benefits of diversification between them. Take note that this value is the same as the squared value of correlation coefficient seen earlier.
14) STDEV: Calculates the standard deviation of a sample.
There are two types of standard deviation formulas – population and sample. The difference between STDEV.S and STDEV.P results arises because they are used for different purposes and handle data slightly differently:
- STDEV.S (Sample Standard Deviation): This function calculates the standard deviation based on a sample of data. It uses n−1 (where n is the number of data points) in the denominator, which is known as Bessel’s correction. This correction provides an unbiased estimate of the standard deviation when the dataset is a sample of a larger population.
- STDEV.P (Population Standard Deviation): This function calculates the standard deviation assuming the data represents the entire population. It uses n in the denominator without Bessel’s correction.
The denominator difference (i.e., n−1 for STDEV.S and n for STDEV.P) leads to a slight increase in the STDEV.S result compared to STDEV.P. This adjustment helps avoid underestimating the variability in sample data, making STDEV.S slightly larger.
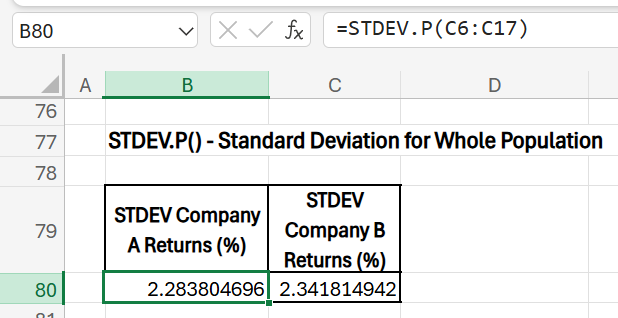
- STDEV.P: Standard Deviation of Monthly Returns (Entire Population)
- Purpose: Measure volatility, or the amount of variation, in returns for each company over the entire dataset.
- Formula (Company A): =STDEV.P(C6:C17)
- Formula (Company B): =STDEV.P(D6:D17)
- Results:
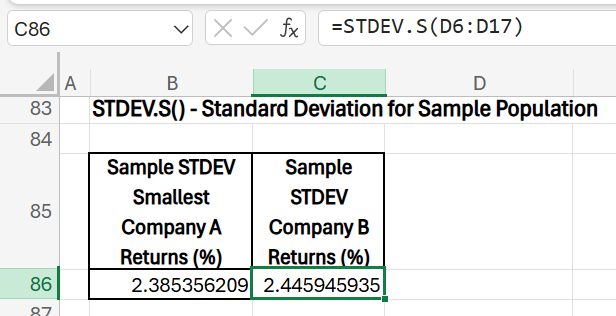
- STDEV.S: Standard Deviation of Monthly Returns (Sample Population)
- Purpose: Measure volatility, or the amount of variation, in returns for each company over the entire dataset.
- Formula (Company A): =STDEV.S(C6:C17)
- Formula (Company B): =STDEV.S(D6:D17)
- Results:
15) VAR: Calculates the variance of a sample.
- VAR.P(number1, number2, …):
Population Variance of Returns
- Purpose: Variance indicates the spread of returns; in finance, it’s another way to measure risk. This is a squared value of the population standard deviation.
- Formula (Company A): =VAR.P(C6:C17)
- Formula (Company B): =VAR.P(D6:D17)
- Results:
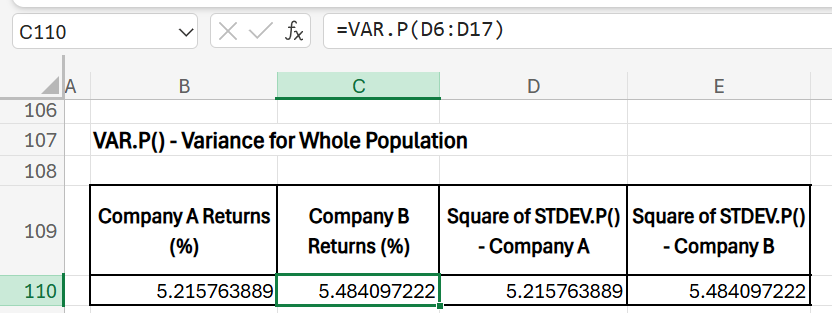
As you see here, variance of a population is nothing but the squared value of standard deviation of a population.
- VAR.S(number1, number2, …):
Sample Variance of Returns
- Purpose: This is useful when working with a subset of historical returns. This is a squared value of the sample standard deviation.
- Formula (Company A): =VAR.S(C6:C17)
- Formula (Company B): =VAR.S(D6:D17)
- Results:
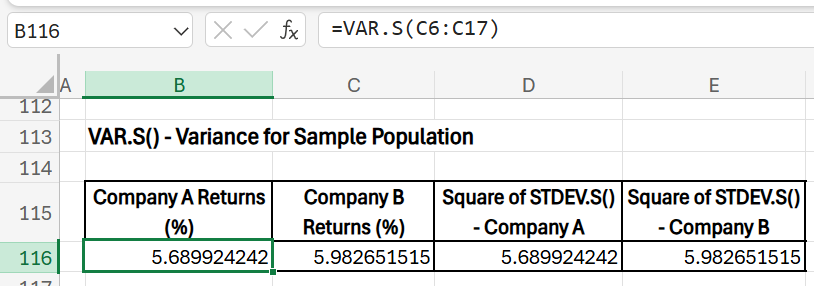
As you see here, variance of a sample is nothing but the squared value of standard deviation of a sample.
**
Probability Distributions Functions in Excel:
1) NORM.DIST(x, mean, standard_dev, cumulative): Calculates the probability density function of a normal distribution
x: The value for which you want to find the probability. This could represent a specific outcome, like a return rate or test score.
mean: The average (mean) of the distribution. This is the central value of the distribution, where most data points cluster.
standard_dev: The standard deviation of the distribution, which measures how spread out the values are around the mean.
cumulative: A logical (TRUE/FALSE) argument – TRUE returns the cumulative distribution function (CDF), which gives the probability of obtaining a value less than or equal to x. FALSE returns the probability density function (PDF), which gives the probability density at exactly x.
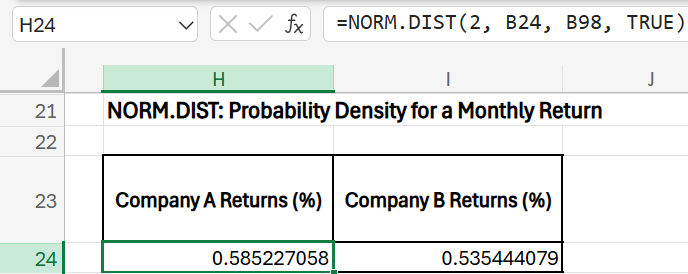
Question: What is the probability of obtaining a market return of 2% or lower in the above data set?
Formula:
Company A: =NORM.DIST(2, B24, B80, TRUE)
Where B24 and B80 have the mean and standard_dev for company A
Company B: =NORM.DIST(2, C24, C80, TRUE)
Where C24 and C80 have the mean and standard_dev for company B
Explanation: The formula calculates the cumulative probability that returns are less than or equal to 2%.
Result:
For Company A : Approximately 0.5852 (or 58.52%). There’s an 58.52% probability of returns being 2% or lower.
For Company B : Approximately 0.5354 (or 53.54%). There’s an 53.54% probability of returns being 2% or lower.
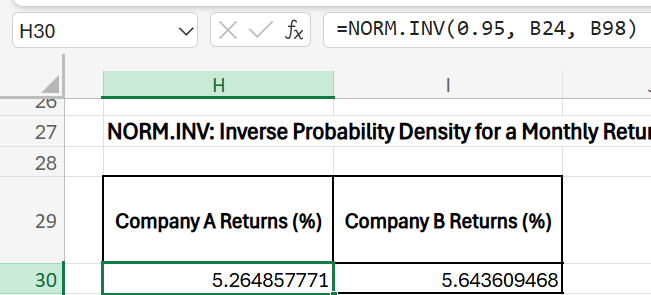
2) NORM.INV(probability,mean,standard_dev): Calculates the inverse of the normal cumulative distribution function.
Question: Find the distribution of the top 5% (95th percentile) of returns in the above market returns data set?
Formula:
Company A: =NORM.INV(0.95, B24, B80)
Where B24 and B80 have the mean and standard_dev for company A
Company B: =NORM.INV(0.95, B24, B80)
Where C24 and C80 have the mean and standard_dev for company B
Explanation (for company A):
- 0.95: The cumulative probability we’re interested in (95th percentile).
- 1.508: The mean monthly return.
- 2.283: The standard deviation of the returns.
- This formula gives the value at which 95% of returns are expected to fall below it, given the distribution parameters.
Interpretation:
For company A – If the result is 5.264%, this indicates that there is a 95% chance of achieving a return below 5.264%. This value is useful in setting risk thresholds for high returns.
3) BINOM.DIST(number_s,trials,probability_s,cumulative): Calculates the probability of a Specific Number of Successes in a Binomial Distribution.
- Number_s: The number of successes in trials
- Trials: The number of independent trials
- Probability_s: The probability of success on each trial
- Cumulative: A logical value that determines the form of the function
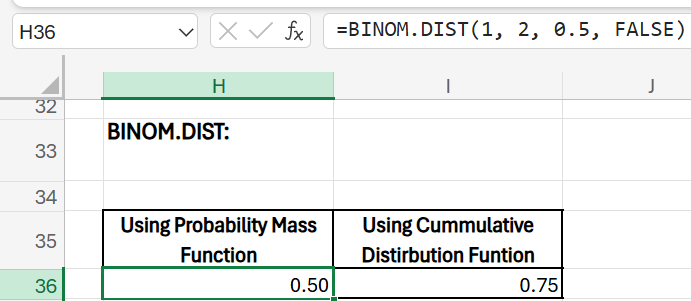
Question: Suppose you flip a fair coin two times and want to calculate the probability of getting exactly one head out of those two flips, where each flip has a 50% chance of resulting in heads.
Formula:
=BINOM.DIST(1, 2, 0.5, FALSE)
Explanation:
- number_s = 15: We are interested in the probability of getting exactly one head.
- trials = 20: There are 2 coin flips in total.
- probability_s = 0.8: The probability of getting heads on each flip is 50%.
- cumulative = FALSE: We want the exact probability of getting one head, not a cumulative probability.
Interpretation:
The result of this formula would give the probability of exactly one head in two flips. For a fair coin with a 50% chance of landing heads, this probability should be 0.5 or 50%. This means there is a 50% chance of getting one head out of two flips.
Possible Outcomes for Two Coin Flips:
- Two Heads (HH)
- Two Tails (TT)
- One Head, One Tail (HT)
- One Tail, One Head (TH)
Since the desired outcome is exactly one head, there are two favorable outcomes (HT and TH) out of four possible outcomes, giving us a probability of 50%. This result helps illustrate how often you can expect one head in two coin flips under ideal conditions.
Other Applications: To calculate the cumulative probability of the head appearing upto 1 time (meaning 0 and 1 time), assuming there is a 50-50 chance of either head or tails appearing, you can use:
=BINOM.DIST(1, 2, 0.5, TRUE)
Out of 4 outcomes, the favourable outcomes for the cumulative distribution would be:
Getting 0 heads (TT): There’s 1 outcome where this happens.
Getting exactly 1 head (HT or TH): There are 2 outcomes where this happens.
The cumulative probability of getting 0 or 1 head includes:
- Probability of 0 heads (TT): 0.25
- Probability of 1 head (HT or TH): 0.25 each (for HT and TH)
So, the cumulative probability for up to 1 head (0 or 1 head) is: 0.25 (TT)+0.25 (HT)+0.25 (TH)=0.75
The result 0.75 means there is a 75% chance of flipping a coin twice and getting no more than one head. It captures all scenarios where the number of heads is either 0 or 1, so it’s a broader probability calculation than just calculating the chance of exactly 1 head.
4) POISSON.DIST(x, mean, cumulative): Calculates the probability mass function of a Poisson distribution. The POISSON.DIST function is useful for calculating the probability of a given number of events happening in a fixed interval of time, given a known average rate. It’s ideal for scenarios where you’re looking at counts over a continuous timeframe, rather than fixed trials.
- x: The number of events for which you want the probability.
- mean: The average number of events in the given interval.
- cumulative: A logical value (TRUE or FALSE) that specifies the form of the function. If TRUE, it returns the cumulative distribution function (the probability of at most x events occurring). If FALSE, it returns the probability mass function (the probability of exactly x events occurring).
Question: Suppose we know that the team receives an average of 30 calls per day. We want to find the probability that they will receive exactly 25 calls on a given day.
Formula:
=POISSON.DIST(25, 30, FALSE)
Explanation :
- x = 25: We’re interested in the probability of receiving exactly 25 calls.
- mean = 30: The average number of calls received per day is 30.
- cumulative = FALSE: We want the exact probability for receiving 25 calls, not cumulative.
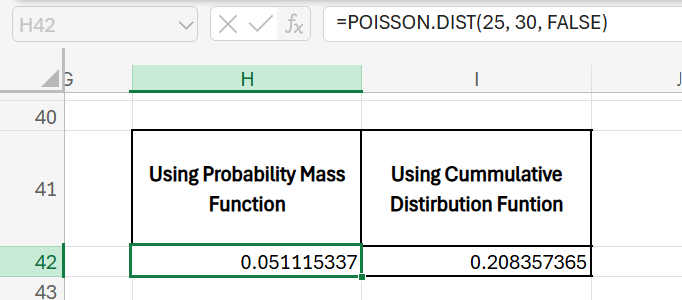
Interpretation: This result suggests that, given an average of 30 phone calls, there is a 5.1% chance of receiving exactly 25 phone calls in the given time period. While this is a relatively low probability (compared to, say, the probability of receiving around 30 calls), it still indicates that such an outcome is possible, just not highly likely. If you’re managing phone call volumes for a customer service centre or similar, this result helps you understand how unusual it would be to receive exactly 25 phone calls in a given period if you expect about 30 calls on average. This can help in workforce planning and capacity management, as you’d know that receiving significantly fewer (or more) calls is less likely, but still possible within the range of normal variation.
Limitations of Excel’s Statistical Functions
While Excel is a powerful tool for statistical analysis, it has certain limitations:
Data Quality and Cleaning
- Missing Values: Excel’s statistical functions often assume complete datasets. Missing values can significantly impact the accuracy of results.
- Outliers: Outliers, or extreme values, can distort statistical measures like mean and standard deviation. Identifying and handling outliers is crucial.
- Data Consistency: Inconsistent data formats or units can lead to incorrect calculations. Ensuring data consistency is essential.
Example: If you have a dataset with missing sales figures for a particular month, the AVERAGE function might produce inaccurate results if not handled properly.
User Error and Misinterpretation
- Incorrect Function Usage: Misunderstanding the parameters and syntax of statistical functions can lead to incorrect results.
To mitigate these limitations, it’s essential to:
- Clean and Validate Data: Ensure data accuracy, consistency, and handle missing values appropriately.
- Check Statistical Assumptions: Use graphical methods and statistical tests to assess the assumptions of statistical tests.
- Consider the Limitations of Excel: For complex analyses, consider using specialised statistical software.
Conclusion
Excel’s statistical functions provide a powerful toolkit for data analysis. By understanding their capabilities and limitations, you can effectively utilise them to gain valuable insights from your data. Remember to clean and validate your data, consider the underlying statistical assumptions, and choose the appropriate functions for your specific analysis.
For more complex statistical analyses or when dealing with large datasets, consider using specialised statistical software. However, for basic statistical computations and data exploration, Excel remains a reliable and accessible tool. By combining Excel’s statistical functions with careful data analysis practices, you can make informed decisions and draw meaningful conclusions from your data! Here’s your free practice sheet to get started: Statistical Functions in Excel.xlsx

